

Whisper 输出重复问题解决方案
最近 Memo 反馈中,有很多是关于转写音频出现重复输出的问题。反馈内容如下:
- 转写经常遇到这个问题.....疯狂重复一句话....
- 视频八分半,从4分钟左右就一直在重复,至到结束
- 识别的时候卡在一句话一直重复这个bug好像现在越来越厉害了,一些以前能正常转写的,现在重新转写都不行了。
- large zh 无法转录长视频,几分钟之后就会不断重复卡死,显存8G
- 请问一下,你们会有识别一句话字幕一直重复的bug吗
常见操作
这类情况根据反馈,我总结了以下几种情况会经常发生幻觉重复问题,但是请注意:因音频质量,设备性能有差异,无法提供统一标准答案。
使用 Large-v3 模型转写
Large-v3 模型出现问题的概率远远高于 Large-v2 和 Large-v1。当然也有人问题,这三者有什么区别?实际没有没有太大区别,最大区别就是 Large-v3 支持粤语的转写。
推荐方案:更换模型重新转写
转写中文或者小语种内容
Whisper 的中文语料肯定是低于英文的,whisper 有个拿前序转录结果提示当前转录结果的思想,所以当前如果单纯识别不出来,就开始依靠前序结果胡编乱造。
推荐方案:更换中文模型转写,或者逐个尝试其他模型。
会议大段空白,电影,音乐等混杂音频
基于 Whisper 推理的方式,如果一段音频中混杂的声音太多,转写失败的概率也就越大。
推荐方案:使用三方工具对音频进行处理,可以谷歌搜索“人声提取”获取对应的工具。
设备性能不足
核心问题还是模型推理需要性能资源不足,造成幻觉。
推荐方式:转写高级设置打开语音检测,换模型,换性能更好的机器。
选错语言,英文视频转中文
如果是英文视频,不要选择中文,AI 推理到一定程度就会出现幻觉。
推荐方案:是什么语言就选择对应语言转写,然后进入字幕页面,右上角翻译即可。
Memo AI 解决方案
大家肯定会问?Memo AI 如何解决这种幻觉重复问题?坦白说很难,因为企业级服务本来运行在稳定高性能的服务器中,出问题概率远远小于本机设备。大家的设备配置参数,系统版本均不统一,很难做到标准化。但是我们也尝试了一些方案。
提示词
以下是我测试可能有效的提示词:
ignore the background sound of the music and only transcribe the part with the human voice.ignore noise, white space, musical background sounds, and transcribe the part that speaks.This is a meeting, transcribe the voice of the conversation in the meeting and ignore the noise具体使用请参考下图。
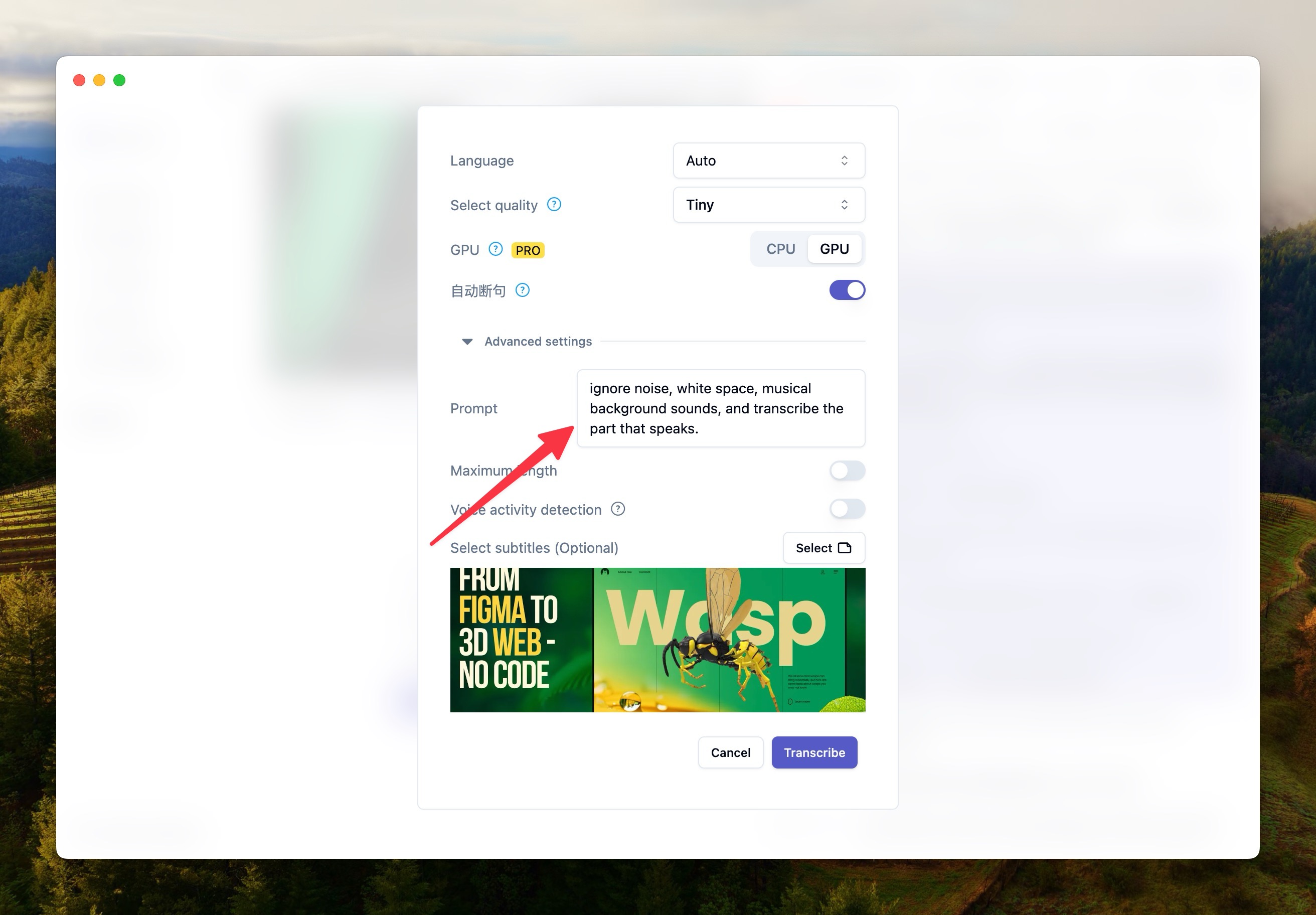
人声检测
whisper 幻觉这个如果是空白时间段导致的,那配合语言活动检测应该相对容易解决。参考下图转写过程中,高级设置中,启用人声检测。
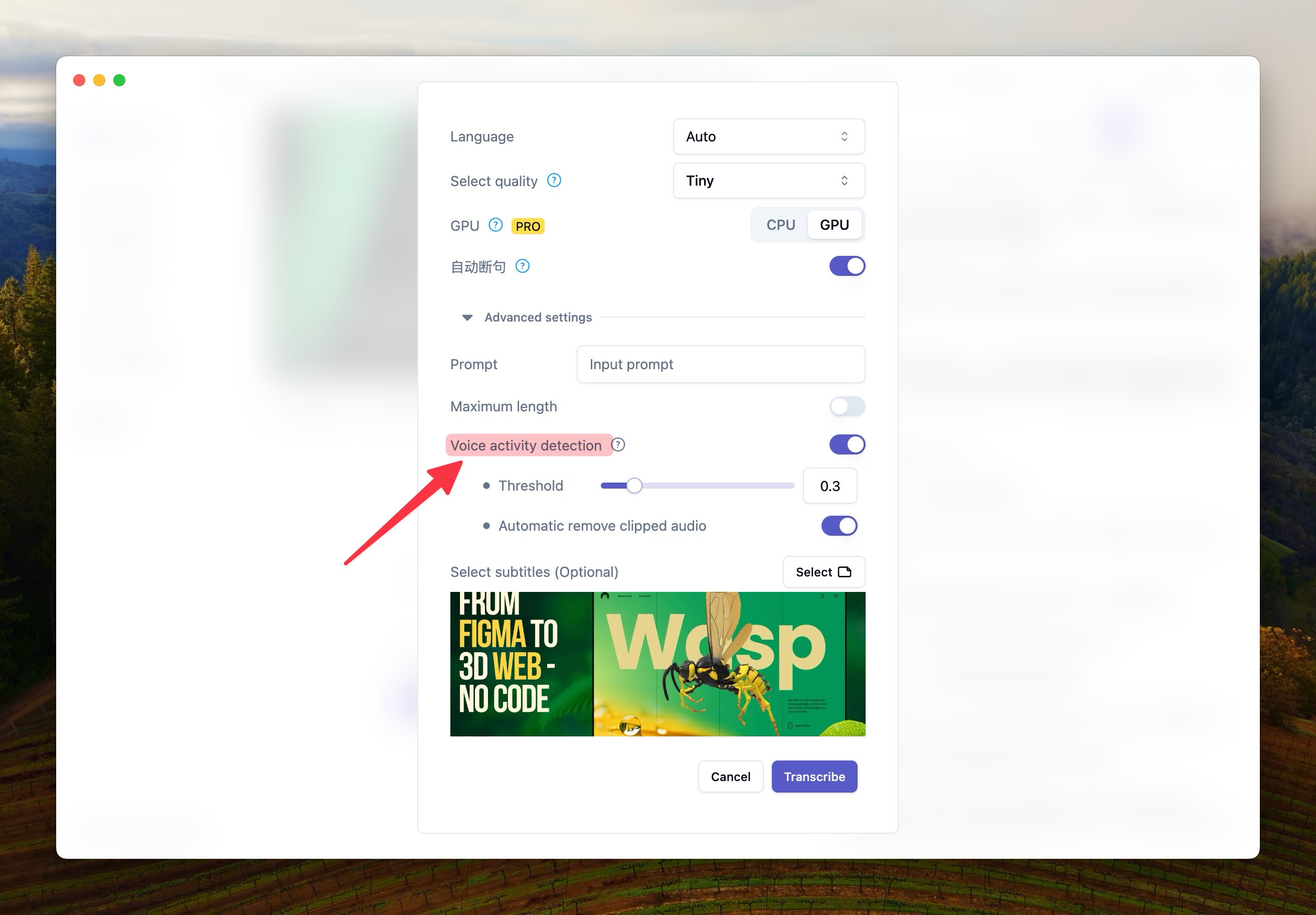
人声检测相应也会有一些小问题,比如错漏部分有声部分,背景音嘈杂部分仍然会出现幻觉。
区域转写
部分有幻觉的地方,你也可以通过右键 - 选择,然后勾选需要转写的部分重新转写。
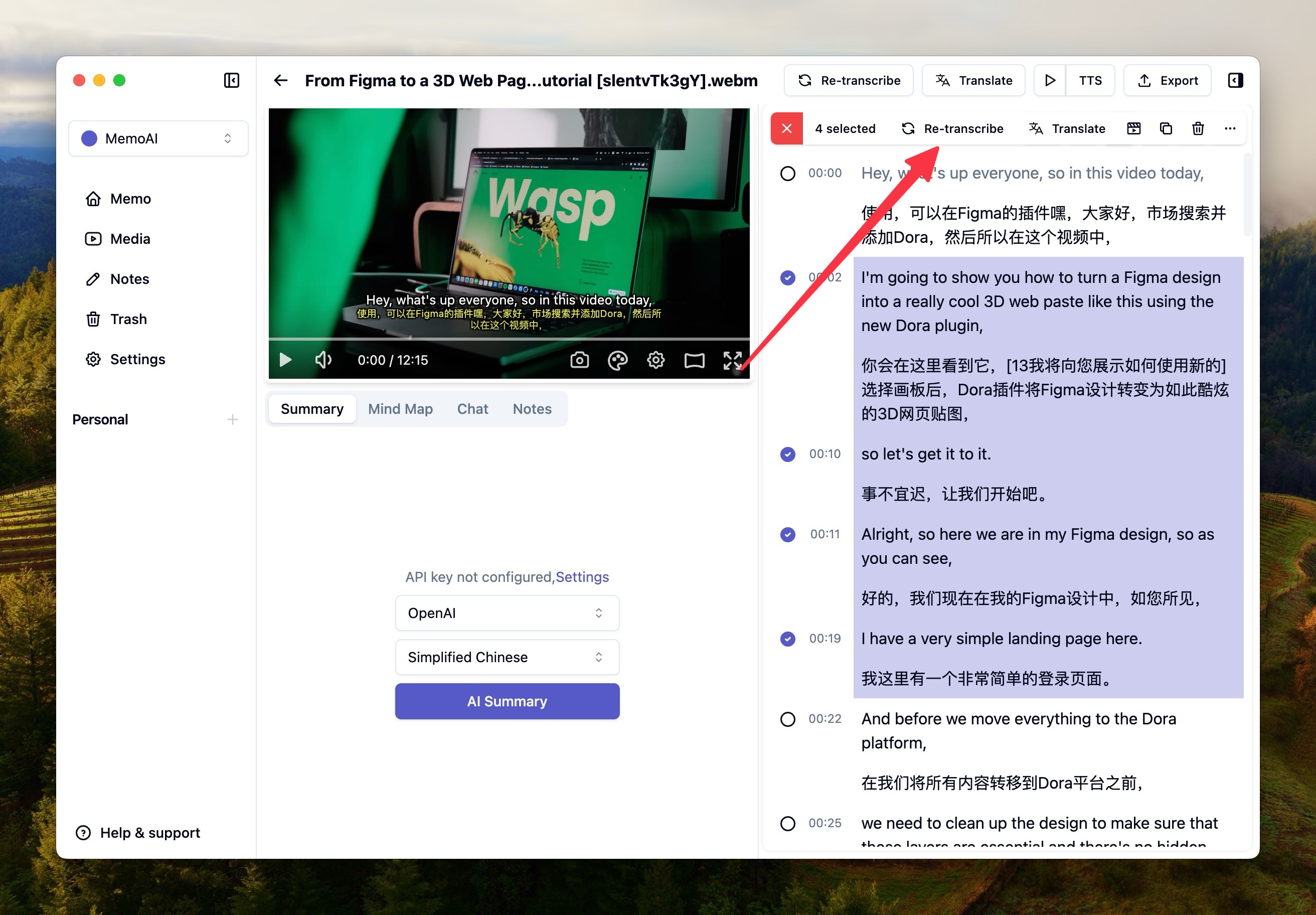
人声分离
这种是最理想的方式,但是经过我们调研,这类人声分离的方式相对耗时,部分机器设备差,一小时视频,分离出来需要一小时,这个对于本地转写速度很不友好。